JavaScript 是网络平台的重要组成部分,因为它提供的很多功能可将网络转变成一个非常强大的应用平台。请设法让用户能够通过 Google 搜索轻松找到您的由 JavaScript 提供支持的 Web 应用,这样做有助于您在用户搜索您的 Web 应用所提供的内容时发掘新用户并再度吸引现有用户。虽然 Google 搜索使用常青 Chromium 来运行 JavaScript,但您可从几个方面进行优化。
本指南将介绍 Google 搜索如何处理 JavaScript,以及与针对 Google 搜索改进 JavaScript Web 应用相关的最佳实践。
Google 如何处理 JavaScript #
Google 对 JavaScript 网络应用的处理流程分为 3 大阶段:
- 抓取
- 呈现
- 索引编制
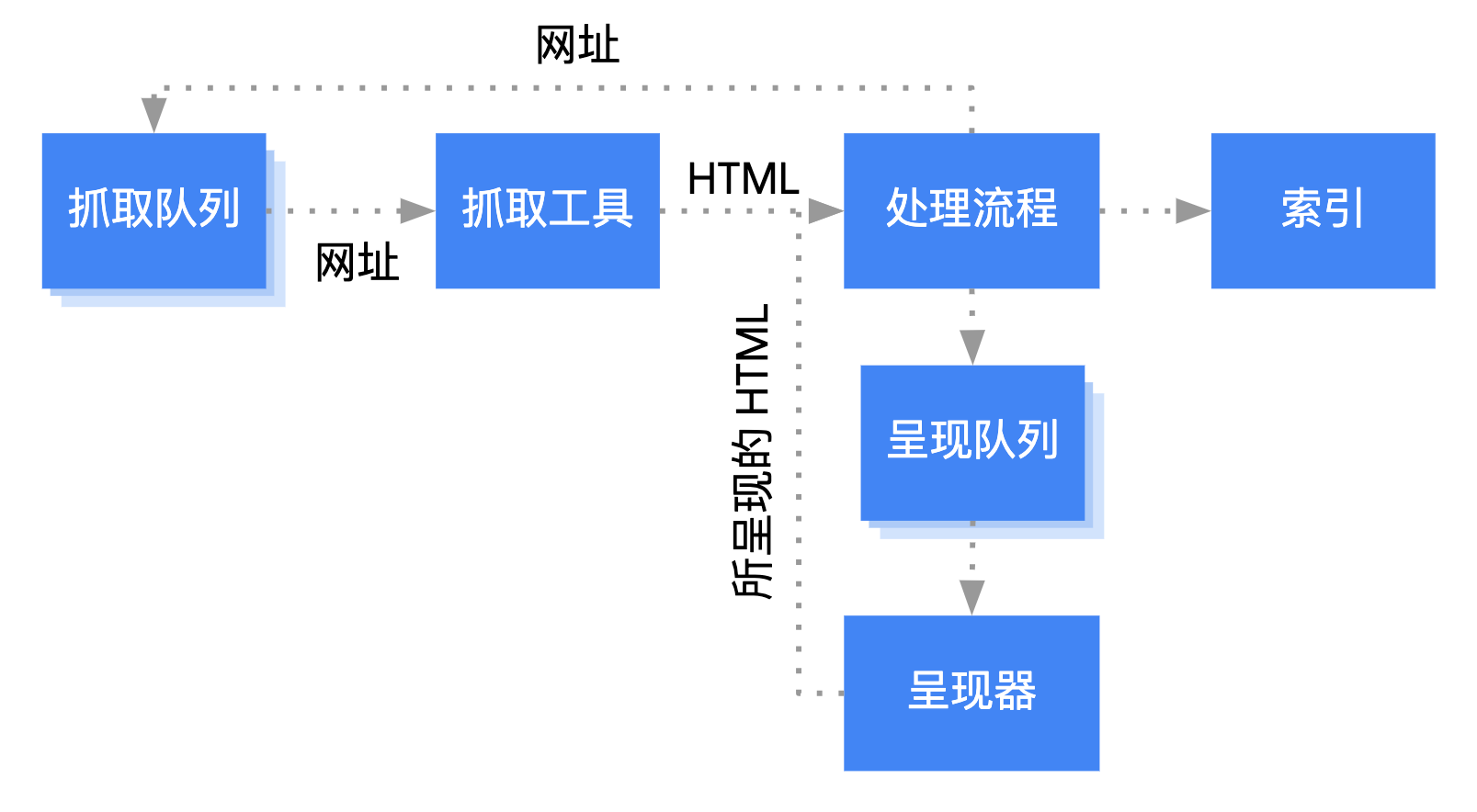
Googlebot 会将网页加入队列以进行抓取和呈现。当某个网页正在等待被抓取/被渲染时,这种状态很难直接判断出来。
当 Googlebot 尝试通过发出 HTTP 请求从抓取队列中抓取某个网址时,它首先会检查您是否允许抓取。Googlebot 会读取 robots.txt 文件。如果此文件将该网址标记为“disallowed”,Googlebot 就会跳过向该网址发出 HTTP 请求的操作,然后会跳过该网址。
接下来,Googlebot 会解析 HTML 链接的 href 属性中其他网址的响应,并将这些网址添加到抓取队列中。若不想让 Googlebot 发现链接,请使用 nofollow 机制。
抓取网址并解析 HTML 响应非常适用于传统网站或服务器端渲染的网页;在这些网站或网页中,HTTP 响应中的 HTML 包含所有内容。某些 JavaScript 网站可能会使用应用 Shell 模型;在该模型中,初始 HTML 不包含实际内容,并且 Google 需要执行 JavaScript,然后才能查看 JavaScript 生成的实际网页内容。
Googlebot 会将所有网页都加入渲染队列,除非 robots meta 标记或标头告知 Google 不要将网页编入索引。网页在此队列中的存在时长可能会是几秒钟,但也可能会是更长时间。一旦 Google 的资源允许,无头 Chromium 便会渲染相应网页并执行 JavaScript。Googlebot 会再次解析所渲染的链接 HTML,并将找到的网址加入抓取队列。Google 还会使用所呈现的 HTML 将网页编入索引。
请注意,依然建议您采取服务器端渲染或预渲染,因为:(1) 它可让用户和抓取工具更快速地看到您的网站内容;(2) 并非所有漫游器都能运行 JavaScript。
用独特的标题和摘要来描述网页 #
独特的描述性 <title> 元素和有用的元描述可帮助用户快速找到符合其目标的最佳结果;我们的指南中解释了怎样才算是良好的 <title> 元素和元描述。
您可以使用 JavaScript 设置或更改元描述及 <title> 元素。
Google 搜索可能会根据用户的查询显示不同的标题链接。 当标题或描述与网页内容的相关度较低时,或者当我们在网页中找到了与搜索查询更相符的替代项时,就会发生这种情况。详细了解为什么搜索结果标题可能与网页的 <title> 元素不同。
编写兼容的代码 #
浏览器提供了很多 API,而 JavaScript 是一种快速演变的语言。Google 对所支持的 API 和 JavaScript 功能有一些限制。若要确保您的代码与 Google 兼容,请遵循我们的 JavaScript 问题排查指南。
如果您使用功能检测机制检测到您所需的某个浏览器 API 缺失了,我们建议您使用差异化渲染和 polyfill。由于无法对一些浏览器功能使用 polyfill,因此我们建议您查看 polyfill 文档以了解是否存在某些限制条件。
编写兼容的代码 #
Googlebot 会通过 HTTP 状态代码确定抓取网页时是否出现了问题。
如需告知 Googlebot 无法抓取某个网页或无法将某个网页编入索引,请使用有意义的状态代码(例如:404 表示找不到网页,401 代码表示必须登录才能访问网页)。您可以使用 HTTP 状态代码告知 Googlebot 某个网页是否已移至新网址,以便系统相应地更新索引。
这里列出了 HTTP 状态代码及其对 Google 搜索的影响。
避免单页应用中出现 soft 404 错误#
在客户端呈现的单页应用中,路由通常实现为客户端路由。 在这种情况下,使用有意义的 HTTP 状态代码可能是无法实现或不实际的。 为避免在使用客户端渲染和路由时出现 soft 404 错误,请采用以下策略之一:
- 使用 JavaScript 重定向至服务器响应 404 HTTP 状态代码(例如 /not-found)的网址。
- 使用 JavaScript 向错误页面添加 <meta name=”robots” content=”noindex”>。
以下是重定向方法的示例代码:
fetch(`/api/products/${productId}`)
.then(response => response.json())
.then(product => {
if(product.exists) {
showProductDetails(product); // shows the product information on the page
} else {
// this product does not exist, so this is an error page.
window.location.href = '/not-found'; // redirect to 404 page on the server.
}
})
以下是 noindex 标记方法的示例代码:
fetch(`/api/products/${productId}`)
.then(response => response.json())
.then(product => {
if(product.exists) {
showProductDetails(product); // shows the product information on the page
} else {
// this product does not exist, so this is an error page.
// Note: This example assumes there is no other robots meta tag present in the HTML.
const metaRobots = document.createElement('meta');
metaRobots.name = 'robots';
metaRobots.content = 'noindex';
document.head.appendChild(metaRobots);
}
})
使用 History API 而非片段 #
只有当链接是包含 href 属性的 <a> HTML 元素时,Google 才能抓取您的链接。
对于实现客户端路由的单页应用,请使用 History API 在 Web 应用的不同视图之间实现路由。为确保 Googlebot 能够解析并抓取您的网址,请避免使用片段加载不同的网页内容。以下示例是一个不好的做法,因为 Googlebot 无法可靠地解析网址:
<nav>
<ul>
<li><a href="#/products">Our products</a></li>
<li><a href="#/services">Our services</a></li>
</ul>
</nav>
<h1>Welcome to example.com!</h1>
<div id="placeholder">
<p>Learn more about <a href="#/products">our products</a> and <a href="#/services">our services</p>
</div>
<script>
window.addEventListener('hashchange', function goToPage() {
// this function loads different content based on the current URL fragment
const pageToLoad = window.location.hash.slice(1); // URL fragment
document.getElementById('placeholder').innerHTML = load(pageToLoad);
});
</script>
不过,您可以通过实现 History API,确保 Googlebot 可以访问您的网址:
<nav>
<ul>
<li><a href="/products">Our products</a></li>
<li><a href="/services">Our services</a></li>
</ul>
</nav>
<h1>Welcome to example.com!</h1>
<div id="placeholder">
<p>Learn more about <a href="/products">our products</a> and <a href="/services">our services</p>
</div>
<script>
function goToPage(event) {
event.preventDefault(); // stop the browser from navigating to the destination URL.
const hrefUrl = event.target.getAttribute('href');
const pageToLoad = hrefUrl.slice(1); // remove the leading slash
document.getElementById('placeholder').innerHTML = load(pageToLoad);
window.history.pushState({}, window.title, hrefUrl) // Update URL as well as browser history.
}
// Enable client-side routing for all links on the page
document.querySelectorAll('a').forEach(link => link.addEventListener('click', goToPage));
</script>
正确注入 rel=”canonical” 链接标记 #
您可以使用 JavaScript 注入 rel=”canonical” 链接标记,但我们不建议这样做。 在呈现网页时,Google 搜索会提取注入的规范网址。 下例展示了如何使用 JavaScript 注入 rel=”canonical” 链接标记:
fetch('/api/cats/' + id)
.then(function (response) { return response.json(); })
.then(function (cat) {
// creates a canonical link tag and dynamically builds the URL
// e.g. https://example.com/cats/simba
const linkTag = document.createElement('link');
linkTag.setAttribute('rel', 'canonical');
linkTag.href = 'https://example.com/cats/' + cat.urlFriendlyName;
document.head.appendChild(linkTag);
});
谨慎使用 robots meta 标记 #
您可以通过 robots meta 标记阻止 Google 将某个网页编入索引或跟踪链接。 例如,在网页顶部添加以下 meta 标记可阻止 Google 将该网页编入索引:
<!-- Google won't index this page or follow links on this page --> <meta name="robots" content="noindex, nofollow">
您可以使用 JavaScript 将 robots meta 标记添加到网页中或更改其内容。以下示例代码展示了如何使用 JavaScript 更改 robots meta 标记以防止在 API 调用未返回内容时将当前网页编入索引。
fetch('/api/products/' + productId)
.then(function (response) { return response.json(); })
.then(function (apiResponse) {
if (apiResponse.isError) {
// get the robots meta tag
var metaRobots = document.querySelector('meta[name="robots"]');
// if there was no robots meta tag, add one
if (!metaRobots) {
metaRobots = document.createElement('meta');
metaRobots.setAttribute('name', 'robots');
document.head.appendChild(metaRobots);
}
// tell Google to exclude this page from the index
metaRobots.setAttribute('content', 'noindex');
// display an error message to the user
errorMsg.textContent = 'This product is no longer available';
return;
}
// display product information
// ...
});
Google 在运行 JavaScript 之前,如果在 robots meta 标记中遇到 noindex,便不会渲染相应网页,也不会将其编入索引。
使用长效缓存 #
Googlebot 会主动缓存内容,以减少网络请求和资源使用量。WRS 可能会忽略缓存标头。这可能会导致 WRS 使用过时的 JavaScript 或 CSS 资源。为了避免这个问题,您可以创建内容指纹,使其成为文件名的一部分(如 main.2bb85551.js)。指纹取决于文件的内容,因此每次更新都会生成不同的文件名。如需了解详情,请参阅 web.dev 长效缓存策略指南。
使用结构化数据 #
在您的网页上使用结构化数据时,您可以使用 JavaScript 生成所需的 JSON-LD 并将其注入网页中。请务必测试您的实现效果,避免出现问题。
遵循网络组件最佳做法 #
Google 支持网络组件。 当 Google 呈现某个网页时,它会扁平化 shadow DOM 和 light DOM 内容。 这意味着 Google 只能看到在所呈现的 HTML 中可见的内容。若要确保 Google 在您的内容渲染后仍能看到该内容,请使用富媒体搜索结果测试或网址检查工具并查看所渲染的 HTML。
如果该内容在所呈现的 HTML 中不可见,Google 将无法将其编入索引。
以下示例会创建一个网络组件,以便在其 shadow DOM 内显示 light DOM 内容。 确保 light DOM 和 shadow DOM 内容均能显示在所呈现的 HTML 中的一种方法是使用 Slot 元素。
<script>
class MyComponent extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: 'open' });
}
connectedCallback() {
let p = document.createElement('p');
p.innerHTML = 'Hello World, this is shadow DOM content. Here comes the light DOM: <slot></slot>';
this.shadowRoot.appendChild(p);
}
}
window.customElements.define('my-component', MyComponent);
</script>
<my-component>
<p>This is light DOM content. It's projected into the shadow DOM.</p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>
呈现后,Google 可以将此内容编入索引:
<my-component> Hello World, this is shadow DOM content. Here comes the light DOM: <p>This is light DOM content. It's projected into the shadow DOM<p> <p>WRS renders this content as well as the shadow DOM content.</p> </my-component>
修正图片和延迟加载的内容 #
图片在带宽和性能方面的开销可能会非常高昂。一种可取的策略是:使用延迟加载方法,仅在用户即将看到图片时才加载图片。若要确保以方便用户搜索的方式实现延迟加载,请遵循我们的延迟加载指南。
以无障碍为设计宗旨 #
针对用户(而不仅仅针对搜索引擎)创建网页。在设计网站时要考虑用户的需求,包括那些可能使用不支持 JavaScript 功能的浏览器的用户(例如使用屏幕阅读器或旧版移动设备的用户)。测试网站可访问性的其中一种最简单的方法是:在停用 JavaScript 后通过浏览器预览网站,或在纯文本浏览器(例如 Lynx)中查看网站。以纯文本形式查看网站还可帮助您找出 Google 难以看到的其他内容,例如图片中嵌入的文字。





